")
Halo, Statistician!
Dalam analisis data, kita sering menemukan kumpulan data yang besar dan kompleks dengan banyak variabel. Data seperti ini sering kali sulit dipahami secara langsung karena tidak menunjukkan pola yang jelas. Oleh karena itu, diperlukan metode eksplorasi data yang mampu mengidentifikasi struktur tersembunyi dalam data tersebut. Salah satu metode yang banyak digunakan dalam statistika multivariat adalah Analisis Cluster (Cluster Analysis). Metode ini memungkinkan kita untuk mengelompokkan data ke dalam beberapa kelompok berdasarkan tingkat kemiripan karakteristiknya. Dalam penelitian di Indonesia, analisis cluster telah banyak digunakan, seperti untuk pengelompokan data sosial, ekonomi, kesehatan, hingga data citra. Hal ini menunjukkan bahwa metode ini memiliki peran penting dalam analisis data nyata dan pengambilan keputusan berbasis data.
📌 Apa itu Analisis Cluster?
Analisis cluster merupakan teknik statistika yang digunakan untuk mengelompokkan objek ke dalam beberapa kelompok (cluster), sehingga objek dalam satu cluster memiliki kemiripan yang tinggi dibandingkan dengan objek di cluster lain. Metode ini bersifat unsupervised learning, artinya tidak memerlukan label awal. Cluster terbentuk berdasarkan kedekatan karakteristik data yang diukur menggunakan suatu ukuran jarak.
Tujuan Analisis Cluster
Tujuan utama analisis cluster antara lain:
- Mengelompokkan data berdasarkan kemiripan
- Menemukan pola tersembunyi dalam data
- Menyederhanakan data multivariat
- Mendukung segmentasi dalam pengambilan keputusan
Konsep Dasar Analisis Cluster
Konsep utama dalam analisis cluster adalah:
- Kemiripan (similarity)
- Jarak (distance)
Semakin kecil jarak antar objek, maka semakin tinggi tingkat kemiripannya. Oleh karena itu, pemilihan ukuran jarak menjadi hal yang sangat penting dalam analisis cluster.
📐 Rumus Jarak Euclidean:
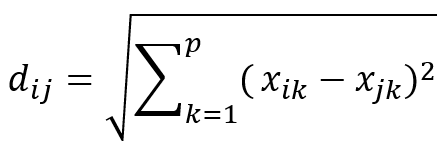
Keterangan:

Metode K-Means Clustering
Salah satu metode paling populer dalam analisis cluster adalah K-Means. Metode ini bekerja dengan membagi data ke dalam k kelompok yang telah ditentukan sebelumnya.
Langkah-langkahnya:
- Menentukan jumlah cluster (k)
- Menentukan centroid awal
- Menghitung jarak setiap data ke centroid
- Mengelompokkan data ke cluster terdekat
- Memperbarui centroid
- Mengulangi proses hingga konvergen
💻 Implementasi Menggunakan Software R Studio (Open Source)
Berikut contoh sederhana:
# Data
data <- data.frame(
x = c(2,3,4,10,11,12),
y = c(2,3,4,10,11,12)
)
# Data
data <- data.frame(
x = c(2,3,4,10,11,12),
y = c(2,3,4,10,11,12)
)
# Standarisasi
data_scaled <- scale(data)
# K-Means
set.seed(123)
hasil <- kmeans(data_scaled, centers = 2)
# Hasil cluster
hasil$cluster
📊 Visualisasi
plot(data_scaled, col = hasil$cluster, pch = 19)
points(hasil$centers, col = 1:2, pch = 8, cex = 2)
🧠 Interpretasi Hasil
Hasil analisis cluster menunjukkan pengelompokan data berdasarkan kemiripan karakteristik. Misalnya:
- Cluster wilayah dengan tingkat kesejahteraan tinggi
- Cluster wilayah dengan risiko penyakit tinggi
Penelitian menunjukkan bahwa clustering mampu memberikan gambaran struktur data yang jelas dan membantu dalam pengambilan keputusan berbasis data.
Kelebihan dan Kekurangan
Kelebihan:
- Tidak memerlukan asumsi distribusi
- Cocok untuk eksplorasi data
- Banyak digunakan dalam berbagai bidang
Kekurangan:
- Sensitif terhadap outlier
- Penentuan jumlah cluster subjektif
- Interpretasi bisa kompleks
📝 Kesimpulan
Analisis cluster merupakan metode penting dalam statistika multivariat yang digunakan untuk mengelompokkan data berdasarkan kemiripan karakteristiknya. Metode ini banyak digunakan dalam penelitian di Indonesia dan terbukti efektif dalam berbagai bidang seperti ekonomi, kesehatan, dan data science. Dengan bantuan software open source seperti R, analisis cluster dapat dilakukan dengan mudah dan menghasilkan informasi yang berguna untuk pengambilan keputusan.
Sumber :
- Suliadi, M.Si., Ph.D., & Reny Rian Marliana, S.Si., M.Stat. (2024). Machine Learning: Unsupervised Learning (Clustering) – Statistika Unisba





